I’m about to start as a Date Engineering Intern working with Zendesk’s Data Engineering (DE) and Data Science (DS) teams. So I’ll be learning to be a Data Engineer, while not knowing in detail what it means to be one. This post should fix that.
Where I Looked For Answers
Somewhat shockingly, Wikipedia does not have an article for “Data Engineering”. You can search around an find that Data Engineers are in growing demand, but still no article. There’s articles for “Information Engineering” and “Knowledge Engineering” but looking at these, they clearly don’t map so well to what we’re talking about.
I found this great answer from Sean McClure to the question “How do I become a data engineer?” on Quora. It is broad and contains enough detail to set you off on the trail of further research. I’m going to use it as a base for my answer, fleshing out that parts that need further information on. On Quora there is also the “What is data engineering?” question, but I thought the answers found there were less clear.
Here We Go.
What Is A Data Engineer?
Make sure you understand that Data Scientist and Data Engineer are not the same thing.
A Data Scientist builds models using mathematics, statistics and machine learning to explain and predict complex behaviour, and codifies those models into real-world software. A Data Engineer designs and builds data architectures for ingestion, processing, and surfacing data for large-scale data-intensive applications.
Ok so data architecture. This is an encompassing term concerned with all processess, methodologies, policies, and standards that set out how data exists and changes in systems. Data can be ‘at rest’ or ‘in motion’ and an architecture manages each state of data.1(https://www.techopedia.com/definition/6730/data-architecture) These two states are high-level and don’t describe anything in detail, but the subject to even too big for a subject on its own.
Data Ingestion is a lot simpler a concept. By ‘ingesting’ data you are accessing data and processing it for immediate use or for storage and later use.2 It is the beginning of a data pipeline, as the data meets and is integrated with the data system.
Apache Kafka, Amazon Kinesis, Apache Sqoop, and Apache Flume are some frameworks/tools for data ingestion. Kafka is a distributed publish-subscribe messaging system. Kinesis is designed for collection and processing of data record streams. Sqoop is designed to transfer bulk data between Hadoop and RDBMSs. Flume is a distributed sysem for collecting log data. Researching these tools will reveal much more about data ingestion as an engineering challenge.
Data Processing is about collecting together of items of data and manipulating that collection to produce meaningful information. Wikipedia provides a nice section on 7 ‘Data Processing Functions’: Validation, Sorting, Summarisation, Aggregation, Analysis, Reporting, Classification. Understanding those seven function together gives you a good idea of what data processing is all about. Apache Hadoop is probably the biggest big data processing tool around today.
Data Surfacing is a term that I hadn’t heard before, and it’s not particularly prevalent on the web. Palantir’s “What We Believe” page provides perhaps the best description of data surfacing by contrasting it with data mining. They say that data surfacing is about bringing up the “totality of known data about a problem in a way that’s easily digestible by the best pattern matching and inference machinery”.3 They say that it is characteristics about the data problem that directs an engineer towards mining or surfacing, so it may be that some data engineers don’t end up doing a lot of the latter.
Often the Data Scientist and Data Engineer will work together to build an end-to-end solution for companies requiring advanced analytical models that are operationalized at scale. The Data Scientist is interested in large scale architecture only insomuch as it allows the “science to scale.” Thus any Big Data project should have a Data Scientist alongside the Data Engineer to ensure that what gets built is analytically sound (no point in engineering a big data architecture that doesn’t prepare and process data in a way that supports the specific models built by the Scientist).
In this context, an end-to-end solution is one where the requirement’s of the client/user are fulfilled entirely by a system. What is built fulfils the ‘data in’ to ‘information out’ steps and everything in between.
My favourite description of operationalization was from Think Big Analytics. operationalization is the focus on taking data science insights and analytics and incorporating them into business units in order to take action in production environment.
The last bolded part of the above paragraph I included because this echoed my experiences of my application to Zendesk’s data engineering team. Through my application I was interviewed by almost all the DE team and by around 4/9 in the Data Science team. It was made clear that there was a close working relationship between the two teams.
As with the Data Scientist there is no formal path to becoming a Data Engineer since it is a unique blend of skills that have been brought together to form a distinct and much needed discipline. The requirements for a Data Scientist are typically more “academic” as they are expected to understand and conduct scientific research and know how to build and test advanced models. PhDs are often sought for Data Science, with backgrounds in the hard sciences or computer science. Data Engineers typically come from an engineering background with less emphasis on the academic background, although many still have Masters degrees. Often developers interested in designing large scale architectures for data-intensive applications can move towards this field as there is much less emphasis on science and math and more on engineering and development.
This part of the answer was concerned more with academic requirements. It does appear to me that there is no “formal path” to a position in DE, and I certainly wasn’t aware of it going into computer science and software engineering at university. I got a sense that there must be a good deal of work involved in what I thought of as the ‘back-end’ of machine learning, data science, and AI. There in fact is, and more and more companies are beginning to grow their DE teams because they contribute to the strength of a company’s machine intelligence.
Since there is less emphasis on advanced academic background it can be easier for someone to move into the Data Engineering field compared to Data Science.
This is an encouraging thing, particularly for someone that is interested in data but is daunted by the prospect of spending 5 years in a PHD after 3-4 years in undergraduate studies. Easier to move into doesn’t mean easy though. Reddit user u/Astra108 talks breifly about the difficulty of DE in this comment.
Data Engineers should understand the core concepts in computer science and should be very well versed in building and designing large scale applications; end-to-end. They should understand the pros and cons of using relational and noSQL databases. They must know how to design effective pipelines for both batch and streaming use cases. They must know what it takes to operationalize a working model and how to help push some of the “lab” specifics (training and validation) into real-time engines. They must understand distributed computing and should be able to work with the Data Scientist to help split algorithms effectively to still yield predictive accuracy across a variety of domains. They should know when to push schemas towards the application to allow for “data lake” designs that assist in large scale analysis but still serve domain-specific applications. And they should be very familiar with the core technologies that are used to build these systems.
The ‘core concepts’ of computer science should be familiar to anybody seeking success in computer science or software engineering. This Quora question has answers that list them well I think.
I think the second bolded text string, about being “well versed…”, is something that can’t really be taught or learnt well outside of industry. Large scale applications can’t be engaged with in the classroom or at home. A good internship or a job will be invaluable in this area.
Relational (SQL) vs NoSQL Databasing is a big topic, but I think Ravindra babu’s stackoverflow introductory answer is a good place to start. I myself have some research to do in this area.
Here we see the first mention of the pipeline. They are a computing element consisting of a set of data processing elements connected one after the other, meaning the output of a previous element becomes the input to another. Think human-centipede style. If you want to look at an open-source pipline check out fluxcapacitor/pipeline.
Distributed Computing is a model of computing whereby networked computers work together by passing data/information/messages along network communication paths. An understanding of distributed computing is absolutely essential for DE as any sufficiently large engineering problem will require distributed vs. monolithic systems.
Splitting algorithms is another thing that I hadn’t heard of, and unfortunately nothing I could find online made sense of the term.
With ‘data lake’ design we’re back to well documented terms. The coiner of the term (James Dixon) forwards an illuminating contrast of ‘data mart’ and ‘data lake’. The data mart is a convienience store filled with bottled water. The water (data) is cleansed and packaged and structured for easy consumption, but you can only consume in one way. The data lake is a large body of water, with the resource in its more natural state. The data lake is there for various users with various needs to examine and collect whatever they need, because everything is there.
The last thing in this paragraph are the core technologies. The following could be considered a solid list on what they would be. To the data enthusiast many would be familiar.
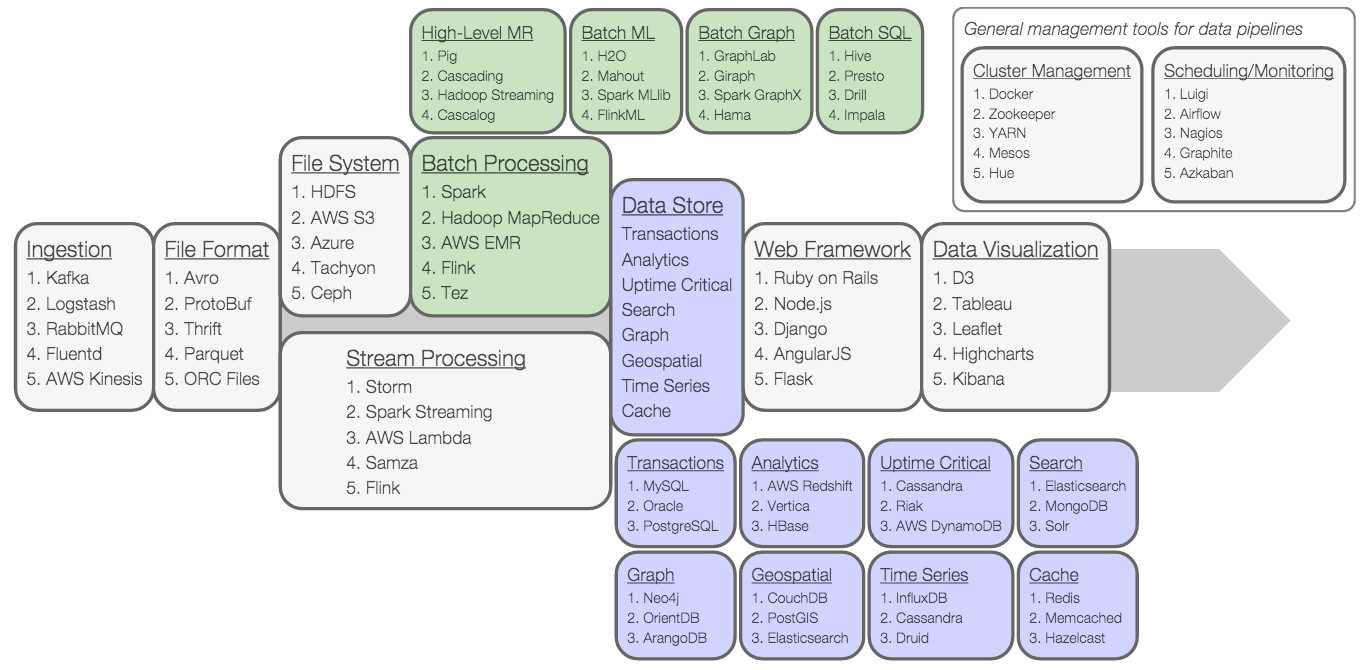
The really important ones would be:
- Apache Kafka
- Hadoop Distributed File System (HDFS)
- Amazon Web Services (AWS) S3
- Apache Spark (Streaming and Batch modes)
- Apache Pig
- Apache Cassandra
- ElasticSearch
- Tableau (visualisation)
- Apache ‘Yet Another Resource Negotiator’ (YARN)
- Luigi (scheduling/monitoring)
- Airflow (scheduling/monitoring)
- SQL
The only way to become great at what you do is to constantly and relentlessly jump into problems and solve them using the techniques and approaches of your choice field. There are many books and tutorials on the technology used by the Data Engineer. Choose a problem and a public dataset and build a system. Build many systems. Fail again and again and learn what it takes to bring an end-to-end solution to a real-world problem. Anyone can take a course or read a book. But if you have real projects you have built and worked on you can point to these and discuss in-depth the challenges you faced and how you solved them.
Yes, yes, you still need to read books in 2016. What a bore. Here are just a few.
Introduction to Probability and Statistics, by Milton and Arnold. McGraw Hill, 1995. ISBN 0-07-113535-9 A primer on probability and statistics, which forms the foundation for data science.
Learning Spark: Lightning-Fast Big Data Analysis, by by Holden Karau, Andy Konwinski, Patrick Wendell, and Matei Zaharia. O’Reilly Media. Feb 2015. (First edition of the book at Amazon.com)
Hadoop: The Definitive Guide, by Tom White. O’Reilly Media. April 2015. (Fourth edition of the book at Amazon.com)
Database Systems: The Complete Book, by Hector Garcia-Molina, Jeffrey D. Ullman, and Jennifer Widom. Prentice Hall. 2008. (The Second edition of the book at Amazon.com)
Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython., by McKinney, Wes. O’Reilly, 2013. ISBN-13: 978-1449319793 “..a practical, modern introduction to scientific computing in Python, tailored for data-intensive applications.”
The Daily Grind
Here’s something more from Jason T Widjaja’s answer to the “What is data engineering question?” that focuses on ‘day to day’ responsibilities.
As for what data engineers do, those in the teams I have worked with deal with data architecture, master data management and data quality. All these terms are worth a Google as there are whole practices built around them. On the ground, daily work consists of:
- managing data stewardship within the organisation
- managing and maintaining data source systems and staging areas
- performing ETL and data conversion
- facilitating data cleansing and enrichment through data de-duplication and construction
- performing ad-hoc data extraction
This short answer introduces yet more terms for us to understand. But I’ll leave these for another time, when I come back and update this post.
Phew, All Done
It’s been about three hours since I first pasted Sean McClure’s answer into my editor for expansion. I’ve come away with a better understanding of the field and a sense of its depth and breadth; I hope you’ve learned a bit by reading.