
If you are consistently using LLMs in any non-trivial task you should make your own private ‘evals’ (a.k.a tests). Take a couple hours, start simple, and shift from passive consumption of AI hype into active, critical tool use. I started after noticing multiple of the staff+ engineers I follow and admire share that they had private evals (1, 2, 3). Both junior and staff+ engineers are heavily using LLMs, but the latter are engaging with the emerging technology in a strikingly different and more productive fashion. Juniors ‘hit and hope’, unsurprisingly awed at the speed and capability of these systems. Senior engineers, on the other hand, apply judgment, skepticism, and taste to LLM output, acting as an essential filter on the token firehose. Private evals are part of that filtering activity.
By ceding openness and control, LLM-driven knowledge work is looking more like Catholic Magisterium. The task of crafting and judging frontier models is vested uniquely in our bishops, those cracked and cracking researchers at OpenAI, Anthropic, Gemini.
They’re telling you it’s a genius. They’re saying it should write almost all code. Next time they release a model, join others in nailing your private evals to their door.
How-to: picking evaluations
As LLMs are such fabulously flexible token generators the landscape of possible fitness tests is impossibly large. You have limited time, and probably want to spend that time exploiting LLMs not evaluating them. So be discerning about what you eval.
The obvious and correct place to start is in your chat history. You’ve had LLMs help on hundreds of problems by now. Pick a few of the most important and interesting to form part of your private benchmarking.
Now having a source of potential evals, the next question becomes how to automate. Automation is important, but from what I’ve seen amongst the private eval crowd there’s too much emphasis on writing scripts and building frameworks to automate pass/fail benchmarking. Expect around half your evals to not be suitable for automation.
Simon Eskildsen has seemingly no automation, tracking his private evals in Notion. That works fine. Don’t overthink it.
The question of automation dealt with, I have some other guidance. Evals should be:
- Something you know a lot about. If you’re an unreliable evaluator, you’ll confuse yourself and not get signal on frontier LLM performance. For example, benchmarks show LLMs smash the Law School Admission Test (LSAT). If you’re a lawyer by all means have private law evals. Otherwise, no.
- Something you care a lot about. If LLMs are as life-and-world changing as the CEOs claim, proto-AGIs, they should help you with what you care about. If it’s cultivating rare strains of tea bush in unfavorable climates, ask about that. 🍵.
- Should be hard for LLMs, should be hard for you. In other words, aim for high ROI. If an eval is easy for today’s LLMs, you’re wasting time and money running the eval. If it’s not hard for you, it doesn’t matter so much that an LLM can do it.
- Diverse. LLMs are obviously useful for programming, but if they’re going to be a technology revolution on the scale of electricity, moveable type, or the internet, they should start being useful to you in most aspects of your life.

How-to: examples
When people talk about their private evals it has an air of teasing about it. They are private after all. “I can’t tell you, internet stranger, without telling the LLMs.” They’re always scraping.
But I can get concrete and specific enough to help you bootstrap an eval set.
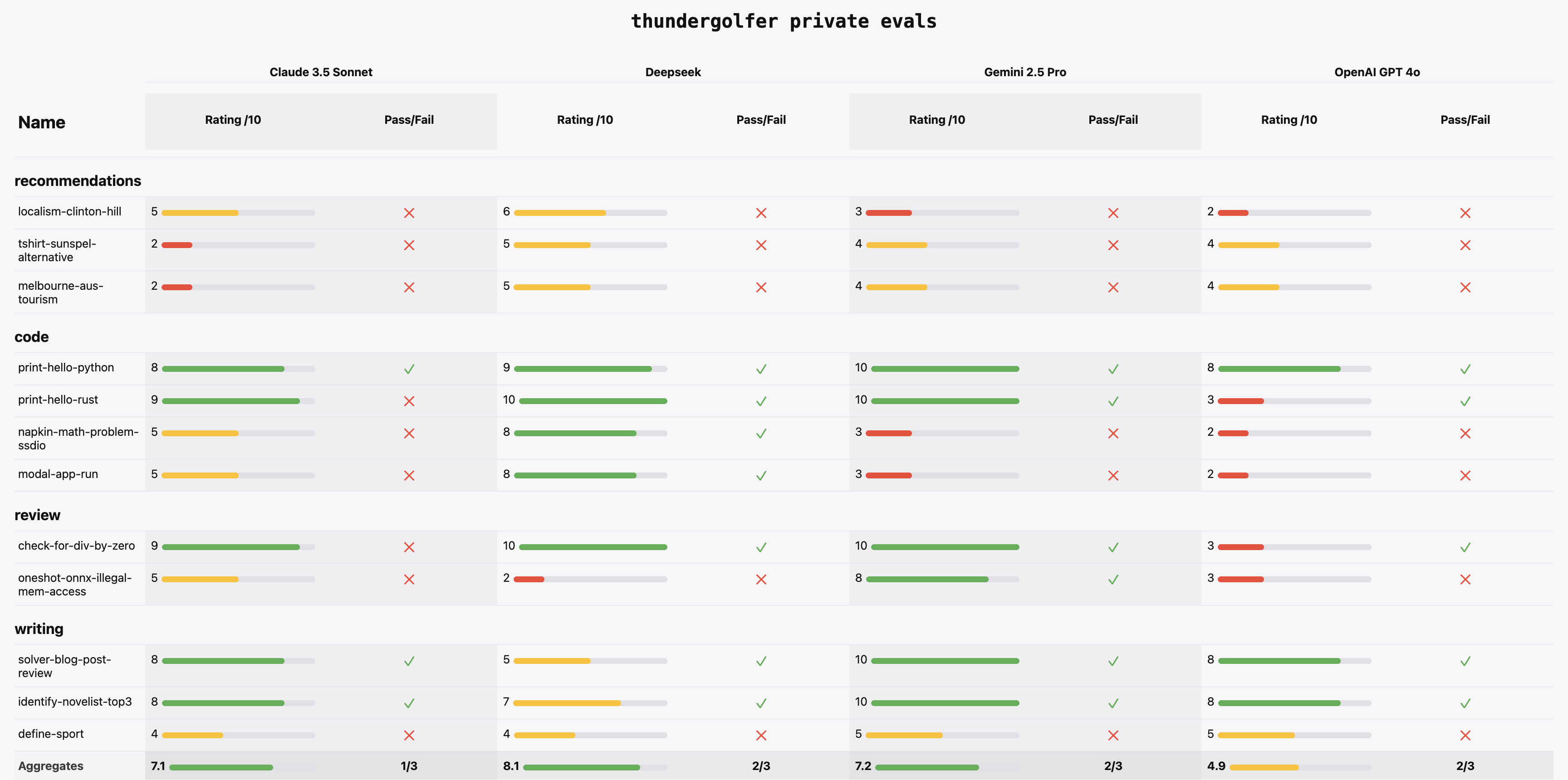
I group my evals into categories. I’ll pick an example from each category: recommendation, review, code, design, writing.
Recommendation:
Good recommendation is hard and valuable. We’re all aware of how Google’s search index and review products are suffering, but can LLMs replace it? Can LLMs, having swallowed Reddit, replace it too?
A recommendation eval I have is asking the LLMs to recommend the best cafe in my local area, based on a few parameters. A knowledgeable local can nail this question. I can answer this question. LLMs currently do poorly. They don’t hallucinate so much, but recommend closed or out of domain places (”here’s something closed in Bushwick. It’s great!”).
It will be interesting to me if they ever get good at this. If they do, I will trust them more with places I don’t know intimately. For now, Reddit is the ‘just fine’ online option. Local peers are best.
Review:
Humans are essential, fallible, and expensive reviewers. Anytime I spot a non-trivial bug in a change set, that’s an obvious candidate as a private review eval.
If you get the LLM to pick out a specific line with the bug in a 100+ line snippet, that’s automatically testable and then you can follow up manually evaluating the explanation.
Excitingly, I’ve found that LLMs are good at review. I have an eval involving arithmetic for a leaky bucket limiter and frontier LLMs can consistently find the edge case bug introduced by the LLM that originally expelled it (Claude 3.5).
Code:
Automated evals for coding should be obvious to any programmer. You write a prompt, you write a test. The LLM reads the prompt, it expels some code, and you run the test.
There’s two interesting bits though. First, you should sandbox the code execution. Second, how do you automate evaluation of code which produces visual output.
Sandboxed code execution I’ll take up down below. For visual evaluation, Nicholas Carlini has a great example of using visual LLMs as judges:
"Write a C program that draws an american flag to stdout." >> LLMRun() >> CRun() >> \
LLMRun("What flag is shown in this image?") >> \
(SubstringEvaluator("United States") |
SubstringEvaluator("USA") |
SubstringEvaluator("America"))
There’s limits to the current visual reasoning capabilities of frontier models, but I think this is pretty neat!
Design:
Problem: figuring out the optimal placement strategy for storing files on a hard drive given a prediction of the file’s future popularity, given that you’re minimizing and maximizing for certain things
Results: Clear winner: o1
I admittedly haven’t spent the time making an eval in this category. I’ll defer to Grant Slatton’s description of his private software design eval: x.com/GrantSlatton/status/1874900859462856977.
Writing:
Before spending time on private evals I was unconvinced that LLMs were either effective writers or editors. After adding private writing evals I now think they can be effective editors.
An example eval here is taking a Modal.com engineering blog post draft that was edited by myself and then completely rewritten and giving it to the LLM to critique. I have to manually review the LLM’s work, but 3 out of 5 provided net-valuable feedback.
How-to: starter code
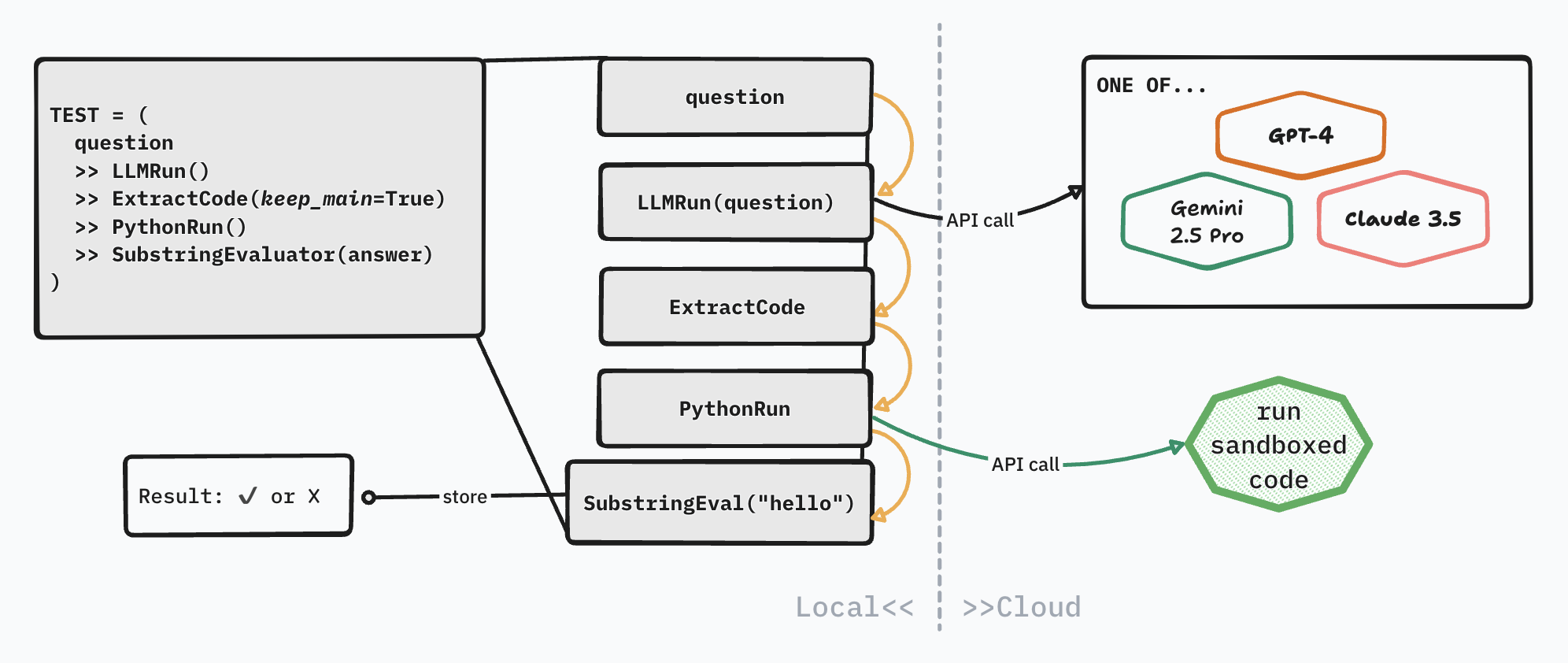
My basic private eval system is, like Edward Yang’s, based off Nicholas Carlini’s YAALLMB. But I don’t recommend forking YALLMB for a few reasons.
- It’s accumulated a lot of complexity to support Carlini’s numerous and sophisticated (public) evals.
- A lot of the code within is LLM generated and frankly janky.
- It relies on a brittle shim to a local Docker or Podman engine.
Instead you can take a look at my significantly stripped down repo: github.com/thundergolfer/private-llm-bench.
See the README for full and up-to-date instructions, but right now it only depends on uv, modal, and an API key for all the frontier LLM providers you’d expect.
The cost to run this is peanuts. Across a dozen or so tests, running on a weekly cron, I’ve spendt 48 cents on OpenAI.
End at the beginning, knowing for the first time.
A key behavior of strong engineers is ‘looking under the hood’ and learning how tools work so that they may be better exploited. Looking under the hood is also how you see tools as tools, and not dark magic. Docker images aren’t magic, they’re just a stack of tarballs.
Given the state of frontier LLM software—very private, very complicated, schotastic, poorly understood—you unfortunately can’t handle them like the rest of your toolkit. But with private evals you can do something that looks more like proper wrench work. And that’s a start.