
What were you doing while the LLM revolution was birthed and in a few short years remade the computing industry?
Was the first LLM really made by an Australian, in between surfs?
These questions have sat with me since I revisited, chronologically, the research papers which scaled up language modelling and the market capitalization of our juggernaut industry by more trillions of dollars.
‘We’ did it. The most famous benchmark in computing history, Turing’s, is now too easy.
Today, dozens of new benchmarks measure the expanding frontier of AI accomplishment: can it win the Putnam, can it beat Pokémon?
In 2016, one year before the ‘first LLM’ was born I was sitting in computer science classes hearing professors talk of Chomsky’s hierarchy of the grammars. In these lectures, they used Turing’s test to inject a little wonder, a little mysticism into the dry mechanics of push-down automata. Would we ever make a program that passed this test?
When the ‘first LLM’ was born I was wrapping up an internship on a team building a language model. It was not large, and wasn’t a transformer, but with hindsight I was relatively close to the LLM revolution. But I wasn’t really paying attention. Most of us weren’t.
In 2016 my teammates made summarizer models which went “Return return return return return return shipment shipment…“, as well as a genuinely state-of-the-art chat bot which genuinely sucked at chatting. I lost faith.
In January 2018, as I wrestled with Golang in my second internship, Australian Jeremy Howard published ULMFit, the first LLM.
Alec Radford published Improving Language Understanding by Generative Pre-Training (GPT-1) on June 11, 2018.
GPT-1 (Generative Pre-Train One) is widely accepted as an LLM. According to many it is the first. But Jeremy Howard claims otherwise. If we’re to understand the LLM birth, we’ll have to mark down what exactly makes an LLM an LLM.
What I've been working on for the past year! https://t.co/CAQMYS1rR7
— Alec Radford (@AlecRad) June 11, 2018
Inspired by CoVE, ELMo, and ULMFiT we show that a single transformer language model can be finetuned to a wide variety of NLP tasks and performs very well with little tuning/tweaking.
What is an LLM?
LLM (noun): a language model which has been so effectively self-supervisedly trained as a ‘next word predictor’ that it can be easily and successfully adapted to many specific text-based tasks.
Having read GPT-1, 2, 3, and a few other papers, this is the definition I like. It’s not a trivial definition, so let’s break it down:
- “is a language model” → the inputs and predicted outputs are components of human written language (e.g. English). These components are not necessarily, and not typically, words. They may be characters, or character sequences (tokens).
- “self-supervisedly trained” → the dataset is unlabelled text from which (x,y) examples are produced. This was an important departure from task-specific, exspesive, labelled text datasets.
- “next word predictor” → the model is given a sequence of words/characters/tokens and must predict what comes next. “The cat in the” → “hat”.
- “easily adapted” → no architectural changes are made to the model; model has few-shot, even one-shot capabilities.
- “successfully adapted” → achieve state of the art performance
- “many specific text-based tasks” → the model can perform classification, question-answering, parsing, and other text challenges with state-of-the-art performance. This is an important leap beyond task-specific language models which are good at one thing and bad at basically everything else.
I’ve conspicuously left out the “large” part of the LLM definition, but it’s implied by the success of the self-supervised generative training. Before a certain parameter size, this language model architecture didn’t work. Nowadays, the largest LLMs are 1000x larger than the smallest.
I’ve also left out any tying down of the LLM category to the transformer architecture. Despite that being the most dominant LLM architecture, others exist (LSTM, Mamba, Diffusion).
Everything else in the definition was I think key to GPT-1 and the ‘LLM moment’.
If you read the GPT-2 and GPT-3 papers they proceed almost straightforwardly from the success of GPT-1. Although GPT-1 does not include the words “large language model” at all, the latter papers do and refer to GPT-1 as such. So GPT-1 is an early LLM, and maybe the first, if its precedents—ULMFit, ELMo, and CoVE—can’t make the claim.
Are any of CoVE, ELMo, and ULMFit LLMs?
Contextualized Word Vectors (CoVE) were an important innovation in transfer learning but are not much like GPT-1. The CoVE vectors were created with supervised learning (on English to German translation) not self-supervised learning, and the vectors only become an initial component in a larger task-specific model.
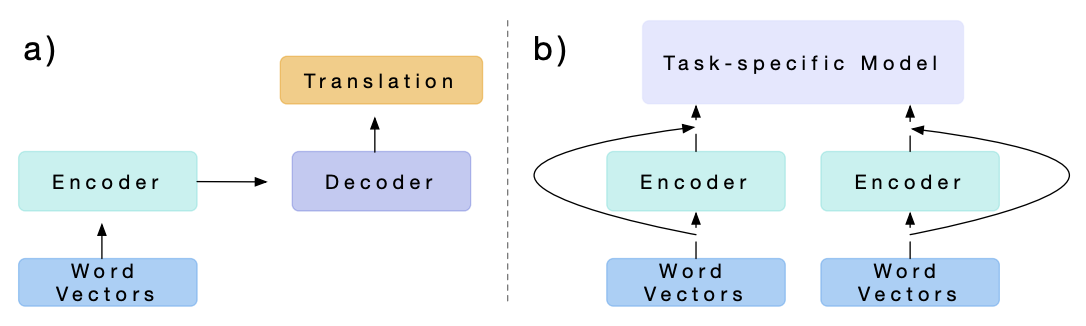
Embeddings From Language Models (ELMo) also trains word embeddings and bolts them into task-specific models. From GPT-1’s Related Work section:
[ELMo and CoVE] use hidden representations from a pre-trained language or machine translation model as auxiliary features while training a supervised model on the target task. This involves a substantial amount of new parameters for each separate target task, whereas we require minimal changes to our model architecture during transfer.
Neither of these is an LLM in my opinion, though for Alec Radford they were clearly stepping stones. Let’s turn to ULMFit then, which the GPT-1 authors say is the “closest line of work to ours”.
Universal Language Model Fine-tuning for Text Classification (ULMFit) is a next-word predictor LSTM self-supervisedly trained on WikiText, adaptable cheaply and without architecture changes to perform a number of text classification tasks with state-of-the-art performance. (Seeing how well ULMFit performed on the IMDb movie review dataset was a 🤯 moment for its author, Jeremy Howard.)
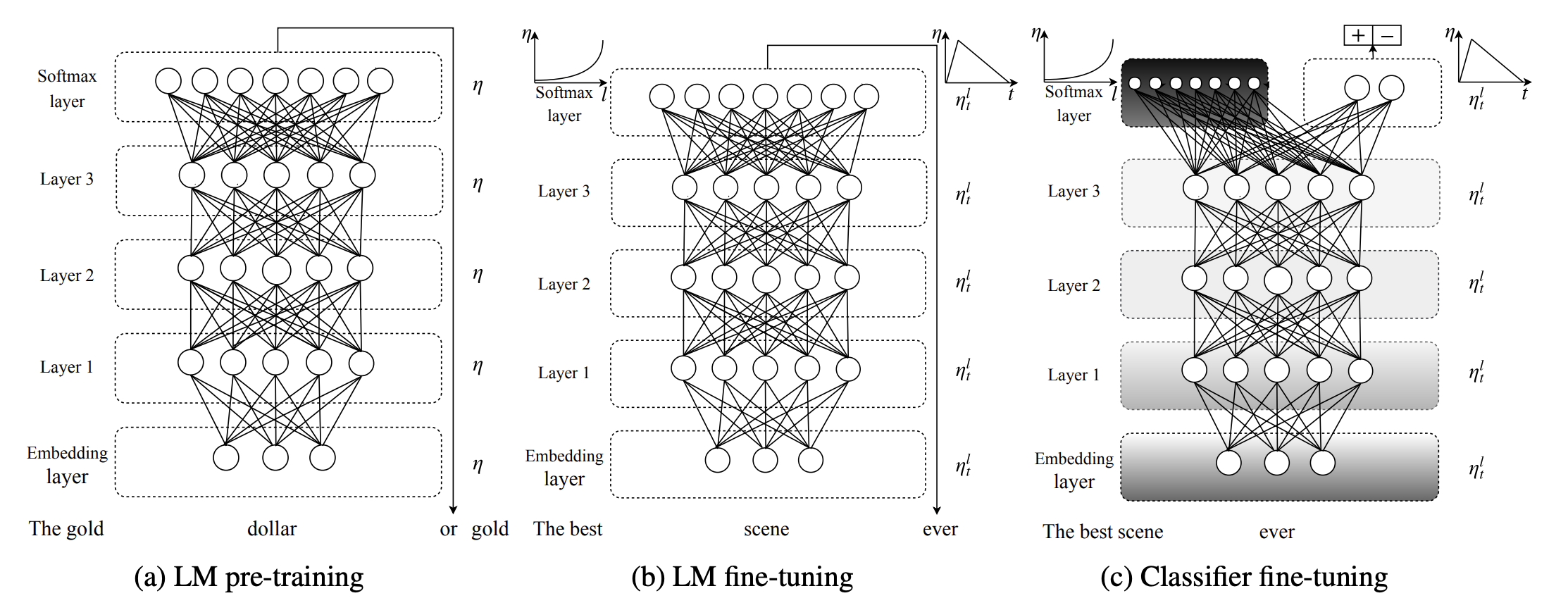
This ULMFit seems a lot like GPT-1 and the above definition of an LLM. The only parts that are arguably not GPT-like are the ease of finetuning and the breadth of applied tasks. The GPT-1 paper fairly calls out the complexity of ULMFit’s “triangular learning rates” and “gradual unfreezing” of parameters. The GPT-1 paper also claims that by swapping at the LSTM architecture for the transformer they unlock wider task-specific competency than ULMFit by lengthening the prediction ability of the pre-trained model.
After trawling back into the past, I’m satisified to call ULMFit the first LLM. This is surely arguable. I’ve not given much attention to Dai and Le’s 2015 Semi-supervised Sequence Learning paper which was the other “closest line of work” called out in the GPT-1 paper. It’s also given more prominence than ULMFit in Radford’s own 2020 history of the GPT moment.
Does being first even matter? I think it does, a bit. The software industry and academia honors its founders. We are all part of a culture that homesteads the noosphere.
ofc the real reason I'm pushing back on this is that I'm worried some folks might realise I didn't actually create the first LLM at on my own at https://t.co/GEOZunWoXj, but that actually I'm just a token figurehead for a CCP conspiracy that created it & had me take credit
— Jeremy Howard (@jeremyphoward) January 25, 2025
Further to the point, understanding the non-OpenAI lineage of LLMs helps understand the competitive dynamics of the industry. Although OpenAI caught their competitors flatfooted, the LLM story was always multi-polar, multi-generational, and geographically diverse. With hindsight we may ask: if Australians can push forward the state-of-the-art, why not China?
The last LLM
Having gone back to the start of the LLM craze, it’s made me curious as to when we’ll see the end of it. GPT-4V was the introduction of image understanding capabilities to the previously text-only model family, and since then the ‘frontier labs’ have gone multimodal. With ChatGPT, Claude, and Gemini adding image and audio processing, it not longer feels apt to call these language models. In place of LLM, we’re seeing increasing (but still minor) usage of “foundation model”.
If I had to guess, I’d say that the term LLM sticks around. It will become like the graphics processing unit (GPU). The general public will eventually be using these models as video-in video-out, and they’ll call them LLMs. What started as a term for something that analyzed IMDb movie reviews will become a term for something that makes movies. At least, that’s how I’ll think about it.
The first LLM was an LSTM pre-trained on Wikipedia and fine-tuned on IMDb movie reviews. GPT-1 crucially subbed in the transformer architecture, cutting out ULMFit’s complexity and offering the industry a scaling ramp that will extend to at least 2030. Many, many more LLMs to come.
Strap in, and maintain attention on the road ahead.

Update: @levelsio and Jeremy Howard got into it over this question on March 29th 2025. Out of that came feedback that I should pay more attention in the post to BERT (“ULMFiT’s first demo predated BERT.”) and the 2015 Semi-supervised Sequence Learning paper.