Do you still want to be a data scientist? The field of deep learning and the data science profession both entered their hype era in 2012. AlexNet’s breakthrough ‘ImageNet moment’ happened in September 2012, and in October 2012 data scientists were declared as having the sexiest job of the 21st century. As deep learning’s hype period enters into its second decade, the hype period for data science appears to be closing out. Lyft and others have renamed their Data Analyst group as Data Science and LinkedIn is rustling with a mass rebranding of technology professionals from “Data Scientist” to “Machine Learning Engineer”. Data scientist is still an appropriate title for many professionals, but in the artificial intelligence & machine learning (AI/ML) space “Machine Learning Engineer” is ascendant. Its ascendance reflects a maturing of the industry’s practices in machine learning powered product and systems development.
It is becoming commonly appreciated that machine learning powered products and systems are mainly plain old software engineering, and that in recent history software delivery teams have over-invested in research and analysis skillsets typically held by data scientists. Given these changes are quickly reconfiguring the AI/ML labour landscape, professionals looking to build a long career in this young space ought to reorient around the much more software focused “Machine Learning Engineer” archetype. As an undergraduate throughout 2015-2018, this was not the obvious move. I started my career in software roles because I thought I couldn’t handle the math in data science, not because I thought data science roles were overhyped.
Data Science: Now only in the top 10 sexiest jobs
Any single individual’s job title or role profile maps only loosely onto their skillset or job responsibilities. Since 2012 there have been data scientists that are elite software engineers and fit perfectly into today’s general understanding of the machine learning engineer archetype. There were software engineers that fit this archetype too. Even today there’s blurriness and contradiction in the communication of what exactly all these roles mean. What’s a ‘data scientist’ versus a ‘research scientist’ versus a ‘machine learning engineer’ versus an ‘applied scientist’? Playing the game of cleanly classifying the differences may just be astrology for tech nerds. Yet there is something to be said for the titling game.
Title bingo matters at least as recruiter bait, and job descriptions can’t all just say “programmer”. The move away from data scientist titling also does reflect a very real industry phenomena. Sometime around 2016, the paper Machine Learning: The High Interest Credit Card of Technical Debt became well acknowledged amongst engineers and a few years later this knowledge percolated up and the executives figured out that this machine learning stuff may be awfully difficult to build. That aforementioned paper aptly describes the principle software artefacts of machine learning development, trained models, as “machines for creating entanglement and making the isolation of improvements effectively impossible.” Jeez, when you put it like that it’s no surprise that engineering machine learning systems is very difficult. ML systems are a breeding ground for insiduous faults and offer a myriad ways to code yourself into a corner; only careful engineering keeps things sane. It was only a matter of time before this reality hit a data science labour market that was underpowered in core software engineering skills.
Machine Learning Engineer is today’s blessed ML title
Into this minor crisis stepped the “Machine Learning Engineer” title and the archetype of an individual that combined strong core software engineering competencies (programming, data structures, operating systems, networking, databases, testing) with theoretical machine learning competencies (a.k.a statistical competencies). That this was a crisis the industry had to have offers indication that sometimes the software industry’s behaviour is irrational and hype driven. To put it crudely, some extremely smart people demonstrated some extremely clever software in a very narrow problem domain and hundreds of uninformed Fortune 500 executives scrambled to join the artificial intelligence boom. Really, the problems with the data scientist archetype should have been apparent from the start.
Twenty years ago Eric S. Raymond was telling us in The Cathedral and the Bazaar that “more than 75% of what programmers get paid to do” is software maintenance. If this is true, how does this fit with the conception of star data scientists whose headline deliverables are supposedly brilliant insights and magic models? Raymond writes:
Most such in-house code is integrated with its environment in ways that make reusing or copying it very difficult. Thus, as the environment changes, work is continually needed to keep the software in step.
Raymond is discussing software in terms of its “use value” (economic utility to a business) versus its “sale value” (price at which you can sell it to customers). In-house code is very difficult to extract out of an internal codebase for sale, therefore in-house software has only “use value”. Crucially, that “use value” is only realised via a significant and ongoing effort to maintain the software. Without maintenance, insights and magic models decay. Acknowledging that machine learning systems are not magic and are more properly seen as a complicated method of entangling data to produce complex program behaviour, is it not obvious that machine learning product and system development should be done by individuals who are predominantly experts in the design of software systems for long-term maintainability?
Well, as an incoming software undergraduate student, it wasn’t really obvious to me. I have been merely lucky that in my own journey towards doing ML in industry I started from the software side. I wanted to pursue data science and get an ML job from the start, but knew I was too weak in mathematics. So data engineering was the safer path, and it has fortunately proved a viable one.
As already noted, machine learning engineering is a relatively new title, with Google Trends indicating it begun its rise in prominence around early 2016. But machine learning applications have been successfully running in industry for multiple decades. So before this title was a thing, were the software maintenance people already performing the machine learning engineer role just mislabelled data scientists? No, I don’t think so. Instead, they were just called software engineers.
Actually though, Software Engineer is the best title
Being a little pedantic and argumentative, I’d argue that the best name for a data scientist, machine learning engineer, research engineer, or whatever, is usually just “Software Engineer”. Any other title draws an unhelpful boundary around your concerns and your competencies, and because the title reflects organisational divisions, titles are, in effect, walls that must over and over be crossed by the systems and people involved in building data-driven or machine learning systems. This problem often painfully manifests when a team ‘runs out’ of needful machine learning work and the business pressures them to pivot to standard software engineering work. “But I’m a machine learning person!” No, unfortunately you were always just a person who solves business problems with software; a software engineer. Something very much like this happened to a team I worked within. If you were always just a software engineer that had the capability to solve problems using machine learning, the problematic boundary on your concerns never existed. Very few companies need serious and continual investment in machine learning. Jumping back to 2016, we can point to individuals who were then delivering machine learning systems under the software engineering title. From the blog post “What They Don’t Tell You About Data Science 1: You Are a Software Engineer First” we have the following description of these ML-equipped software engineers.
[These software engineers] can read all the latest papers on a given AI/ML topic, then implement, test and productionise a state of the art recommender/classifier/whatever - all without breaking a sweat - and then move on to non-data related projects where they can make more impact. One well known example of such a person is Erik Bernhardsson - the author of Annoy and Luigi.
Erik is indeed someone who was running around at Spotify as a software engineer doing ML when it was needed and doing other stuff, such as setting up a data warehouse, when it was not. For other examples we have software engineers Oscar Boykin and Sam Ritchie hacking ML systems at Twitter and Stripe. Josh Wills is another: Staff Software Engineer at Google, Director of Data Science at Cloudera (around the 2012 hype cycle peak), and then back to Software Engineer at Slack and WeaveGrid.
Now these drive-by DS/ML engineers are all highly skilled, labour market ‘unicorns’ 🦄, as they’re sometimes called by hiring managers. They don’t need to serve as the bar to clear; they’re instances of an archetype around which DS/ML excellence is now organised. Their careers and achievements provoke reconsideration of that famous Data Science Venn diagram intersecting “programming”, “statistics”, and “domain knowledge”. A Venn diagram communicates an intersection space, but more salient would be a diagram emphasising some relative scaling to reflect the true importance of each sphere. A stacked pyramid could do this, and would appropriately echo the “data science hierarchy of needs” pyramid diagram, which has a fat base of core software engineering and SQL. I actually think that “domain knowledge” is significantly underplayed in these sorts of diagrams, but let’s put that aside and just make the claim that the software engineering part of things is most of the work. An increasingly appreciated key reason for this is that datasets are more important than fancy modelling. If that’s true, then most engineering investment ought to be put into the enormous software engineering task of collecting, refining, and maintaining high-quality datasets at scale. Furthermore, the increasing prevalence of plug-and-play solutions in certain machine learning domains is markedly lowering the barriers to entry, further increasing the relative value of software competency when compared with the applied math & statistics part.
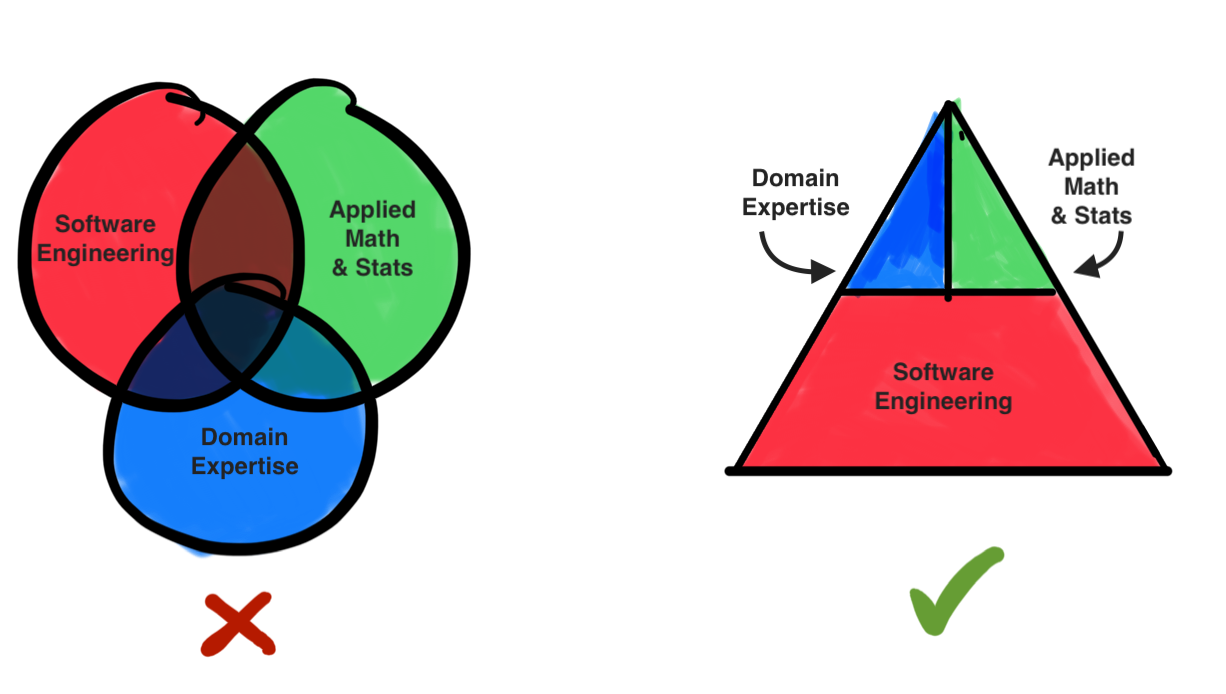
Software engineering focused machine learning engineers are here for the long haul
Accepting the ascendence of machine learning engineering as the majority title and archetype in industry, and recognising that it has its roots in the successes a particular kind of software engineer was having half a decade ago, we can arrive at the conclusion that leaning into the software engineering dominated machine learning engineer archetype is the best for the typical individual’s long term career. This is because the industry is at a place where core software skills are highly valued in machine learning systems development, but also because there is growing sentiment that it’s easier to train strong software engineers for ML than it is to train strong software engineering skills into a data science labour pool that is typically weak in that area.
If you have to choose between engineering and ML, choose engineering. It’s easier for great engineers to pick up ML knowledge, but it’s a lot harder for ML experts to become great engineers. - Chip Huyen
For me though, what’s most important about choosing to invest in a software engineering heavy skillset is that being dominant in core software engineering skills provides more career optionality than being dominant in research and statistical analysis skills. It is uncontroversially true that most necessary software development is just CRUD. In the portion of software development that is not CRUD, core software engineering competency is almost always more valuable than research and statistical analysis competency. This is true across the industry and also even within the individual companies best known for machine learning excellence. A real need for machine learning typically only shows up at a company when they’ve already nailed execution on some other important software development or product activity, and even then it’s a minority activity within the organisation. “In the majority of all products, machine learning will not be a key differentiator in the first five years.”
In probably 90% of all companies, possibly even multi-billion dollar ones, the most effective, impactful data-oriented individual contributor is a software engineer doing drive-by data science when that data science is most fruitful. A software engineer doing drive-by data science is value focused, and software focused, which is ideal because value (almost always money for investors) is the raison d’etre of our places of work, and software development-plus-maintenance is the primary method of that value creation.
How to become a Machine Learning Engineer ‘unicorn’
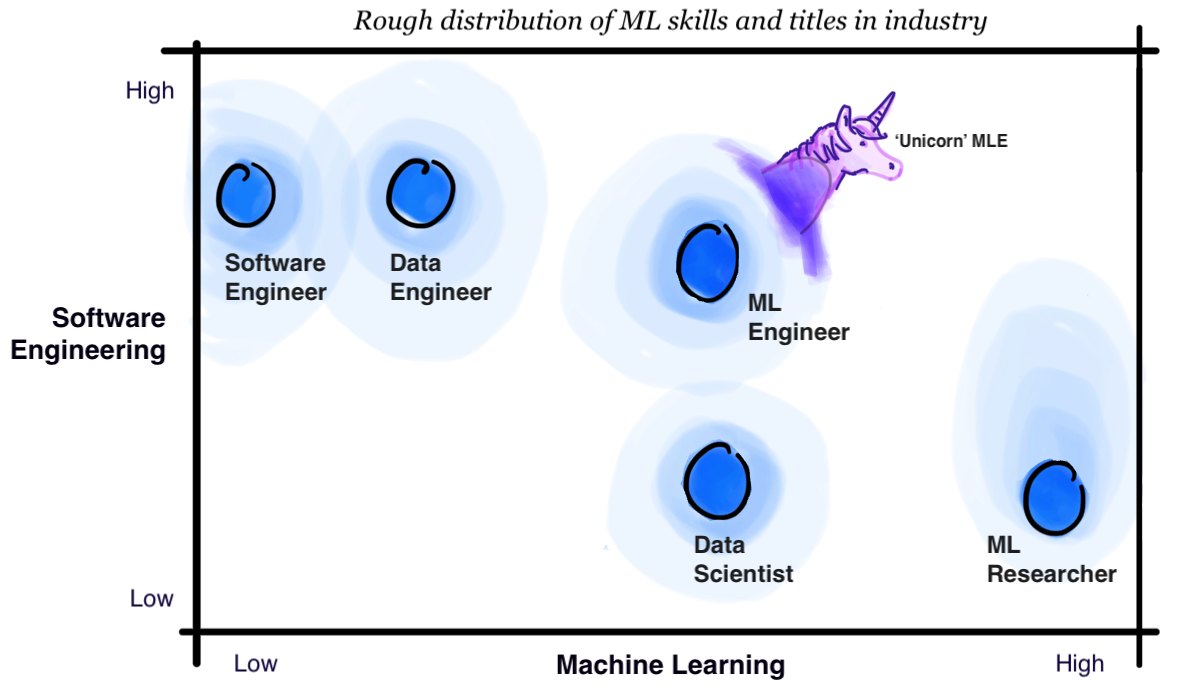
For those not already in prime position at the upper right of an XY graph measuring software engineering skill and machine learning skill, what’s the next move? I believe that those targeting a machine learning engineering role (possibly even from an existing Data Science position) should feel confident in investing the majority of their time in core software engineering skills, at least until they’re strong enough to grab engineering roles in a data team.
For a good quality and up-to-date resources on building towards machine learning engineering roles I’d recommend combining Chip Huyen’s ML Interviews GitBook with the following general backend engineering resources:
- System Design Primer
- Designing Data Intensive Applications
- Effective Java and a buttload of hours writing backend server code.
After almost 10 years of frankly insane hype around artificial intelligence and machine learning — the AI robots are coming for all the jobs! — it may feel a little strange to have the industry reorienting around a sentiment that 90% of machine learning development is just bog-standard software engineering, but here we are. And if the Lindy Effect is active, then this past decade offers confidence that this era of software engineering is far away from being replaced by machine learning driven ‘Software 2.0’. If you are somebody already working in this space or looking to move in, building your human capital according to the machine learning engineer archetype is the surest bet for long-term career viability.
Thank you to Ryan Lyn, Denis Ruderman, and Keeli Smith for reviewing a draft of this post.
Further Reading
- Data Scientist: The Sexiest Job of the 21st Century (2012)
- What’s in a Name? The semantics of Science at Lyft
- Lyft renaming data analysts to data scientists
- “Classifying (MLE vs. data scientist vs. other) across more than two companies is just astrology for math nerds”
- Science as amateur software development
- What machine learning role is right for you?
- The second diagram in my post is heavily influenced by a diagram in this linked presentation.
- Data science is different now by Vicki Boykis