
Modal just brought NVIDIA’s L40S GPU to the platform. This GPU’s datasheet lists it as offering 48GB of VRAM. A customer yesterday asked about why he was only seeing 46,068 MiB out of the nvidia-smi report. He thought we might have short changed him, kept 2GB for ourselves!
We don’t take secret slices out of customer’s GPUs. You get a full, unadulterated, dedicated device.
The first thing to understand is that mebibyte (MiB) ≠ megabyte (MB), and 1 gibibyte (GiB) very much does not equal 1 gigabyte (GB). It’s a shame that the industry still plays fast and loose with the distinction between the SI (base-10) vs. IEC (base-2) units. One terabyte (TB, base-10) is these days a common amount of data to worry about, and it is almost 10% smaller than one tebibyte!
Internally I point at Oxide’s Standard Units For Counting Bits public RFD when we run into unit communication issues. (It’s so nice that Oxide publicizes their high quality discussion documents!) This is something that engineers should just get right, even if computer product marketers have long preferred rounding up and saying the bigger number (GB).
NVIDIA’s product marketing follows the computer storage industry tradition of using nice, round gigabyte numbers. Here’s a table showing the product marketing memory size for every NVIDIA GPU we offer at Modal, alongside the actual memory capacity as reported by NVML (via nvidia-smi).
| GPU | Product size | Actual, MiB | Actual, GiB | Actual, GB | Diff % |
|---|---|---|---|---|---|
| H200 | 141 GB | 143,771 MiB | 140.40 GiB | 150.75 GB | +6.91% |
| H100 | 80 GB | 81,559 MiB | 79.65 GiB | 85.52 GB | +6.90% |
| A100 80GB | 80 GB | 81,920 MiB | 80 GiB | 85.89 GB | +7.36% |
| A100 40GB | 40 GB | 40,960MiB | 40 GiB | 42.94 GB | +7.35% |
| A10 | 24 GB | 23,028 MiB | 22.49 GiB | 24.15 GB | +0.63% |
| L40S | 48 GB | 46,068 MiB | 44.99 GiB | 48.30 GB | +0.63% |
| L4 | 24 GB | 23,034 MiB | 22.49 GiB | 24.15 GB | +0.63% |
| T4 | 16 GB | 15,360 MiB | 15 GiB | 16.11 GB | +0.69% |
What’s interesting here is that NVIDIA GPUs substantially overprovisions the gigabytes on their newer generation GPUs. The H200 product claims 141 GB (why not 140?) but delivers almost 7% more memory!
What explains this difference? I wondered if the extra memory was actually usable or if it was reserved. If it was all actually reserved and unavailable then it makes sense for the marketing to only include the usable memory. But if it’s not all reserved, why overprovision by ~7%?
Let’s analyze the H100 specifically, which claims 80GB of memory in product marketing but reports 85.52 GB (+6.9%).
Is the extra 5.52GB (5.14 GiB) reserved?
We can easily get NVIDIA’s System Management Interface tool, nvidia-smi, to give us a view on the GPU’s memory breakdown:
$ nvidia-smi --query --display MEMORY --id 0
==============NVSMI LOG==============
Timestamp : Sat Jan 25 22:19:18 2025
Driver Version : 550.90.07
CUDA Version : 12.4
Attached GPUs : 8
GPU 00000000:0F:00.0
FB Memory Usage
Total : 81559 MiB
Reserved : 336 MiB
Used : 74624 MiB
Free : 6601 MiB
BAR1 Memory Usage
Total : 131072 MiB
Used : 4 MiB
Free : 131068 MiB
Conf Compute Protected Memory Usage
Total : 0 MiB
Used : 0 MiB
Free : 0 MiB
Before getting into these numbers, let’s get byte-level numbers with no rounding.
Using NVML directly
nvidia-smi is an indispensible workhorse but for programmatic and accurate engagement with NVIDIA devices you’re better off using NVIDIA Management Library (NVML) directly. Thankfully it’s easy! To query device memory statistics use the nvmlDeviceGetMemoryInfo_v2 and nvmlDeviceGetBAR1MemoryInfo functions. I forked Rust’s NVML wrapper crate and added these device query functions. Then a simple Rust main.rs can give us the memory statistics without using nvidia-smi.
use nvml_wrapper::Nvml;
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
let nvml = Nvml::init()?;
let devices = nvml.device_count()?;
println!("Found {} NVIDIA devices", devices);
let device = nvml.device_by_index(0)?;
let memory = device.memory_info_v2()?;
let bar1_memory = device.bar1_memory_info()?;
let name = device.name()?;
println!("\nDevice {}: {}", i, name);
println!("Total memory: {} bytes", memory.total);
println!("Free memory: {} bytes", memory.free);
println!("Used memory: {} bytes", memory.used);
println!("Reserved memory: {} bytes", memory.reserved);
println!("BAR1 total memory: {} bytes", bar1_memory.total);
// Convert to GB for readability
let gb = 1024.0 * 1024.0 * 1024.0;
println!("\nBIn gibibytes:");
println!("Total memory: {:.2} GiB", memory.total as f64 / gb);
println!("Free memory: {:.2} GiB", memory.free as f64 / gb);
println!("Used memory: {:.2} GiB", memory.used as f64 / gb);
println!("Reserved memory: {} GiB", memory.reserved as f64 / gb);
println!("BAR1 total memory: {} GiB", bar1_memory.total as f64 / gb);
Ok(())
}
Running this on an Oracle Cloud H100 worker host we get this:
Found 8 NVIDIA devices
Device 0: NVIDIA H100 80GB HBM3
Total memory: 85520809984 bytes
Free memory: 67314843648 bytes
Used memory: 17854300160 bytes
Reserved memory: 351666176 bytes
BAR1 total memory: 137438953472 bytes
In gibibytes:
Total memory: 79.65 GiB
Free memory: 62.69 GiB
Used memory: 16.63 GiB
Reserved memory: 0.3275146484375 GiB
BAR1 total memory: 128 GiB
So it’s a no. The extra 5.52GB (5.14 GiB) is not all reserved, only 335.375 MiB is. We have 5.169 GB (4.814 GiB) left.
Let’s try allocate it all.
Wait, reserved VRAM varies across clouds ⁉️
Weirdly, the amount of reserved memory varies across the Oracle Cloud and Google Cloud H100 instances I tried. The Google Cloud a3-highgpu-8g instances have 564.06 MiB reserved, 1.68x what’s found reserved in Oracle Cloud. This is highly surprising to me, and I don’t yet know why this would be so.
| Cloud | H100 reserved memory |
|---|---|
| Oracle | 335.37 MiB |
| 564.06 MiB | |
| Vultr | 564.06 MiB |
| AWS | ?? |
This will clearly affect analysis so I’ll call out below which cloud provider is being used.
Finding max allocatable
Modal makes it super easy to run a quick script against an H100 GPU and find out how much memory we can allocate.
import os
import subprocess
import modal
image = modal.Image.debian_slim().pip_install("torch~=2.5.1", "numpy~=2.2.2")
app = modal.App("cuda-probe", image=image)
gpus = ["t4", "l4", "l40s", "a10g", "a100-40gb", "a100-80gb", "h100"]
gpu = gpus[-1] # do h100
@app.function(gpu=gpu)
def measure_max_gpu_memory():
import torch
cloud = os.getenv("MODAL_CLOUD_PROVIDER")
print(f"running on {cloud} cloud provider")
print(f"running on {torch.cuda.get_device_name(0)}")
allocated = []
chunk_size = 10 * 1024
try:
while True:
tensor = torch.zeros(chunk_size, device="cuda", dtype=torch.float)
allocated.append(tensor)
except RuntimeError as e:
if "out of memory" in str(e):
print("OOM!")
# PyTorch view
max_gib = torch.cuda.max_memory_allocated() / (1024**3)
max_gb = torch.cuda.max_memory_allocated() / (10**9)
print(f"\nMax GPU memory allocated: {max_gib:.4f} GiB ({max_gb:.4f} GB)")
max_gib = torch.cuda.max_memory_reserved() / (1024**3)
max_gb = torch.cuda.max_memory_reserved() / (10**9)
print(f"\nMax GPU memory reserved: {max_gib:.4f} GiB ({max_gb:.4f} GB)")
print(torch.cuda.memory_stats(device=0))
# NVIDIA SMI
print("\nnvidia-smi output:")
subprocess.run(["nvidia-smi"], check=True)
else:
raise e
modal run this script repeatedly and (on the same cloud) you’ll consistently see the same numbers printed after the GPU rejects a 10KiB allocation with an OOM error. (Doing 10KiB allocations is kinda slow, but gives us a higher resolution.)
The terminal logging below was from a GCP run, so we expected to allocate 85.52 - 0.591 = 84.929 GB, because we found that 591.4 MB (564.06 MiB) is reserved on GCP.
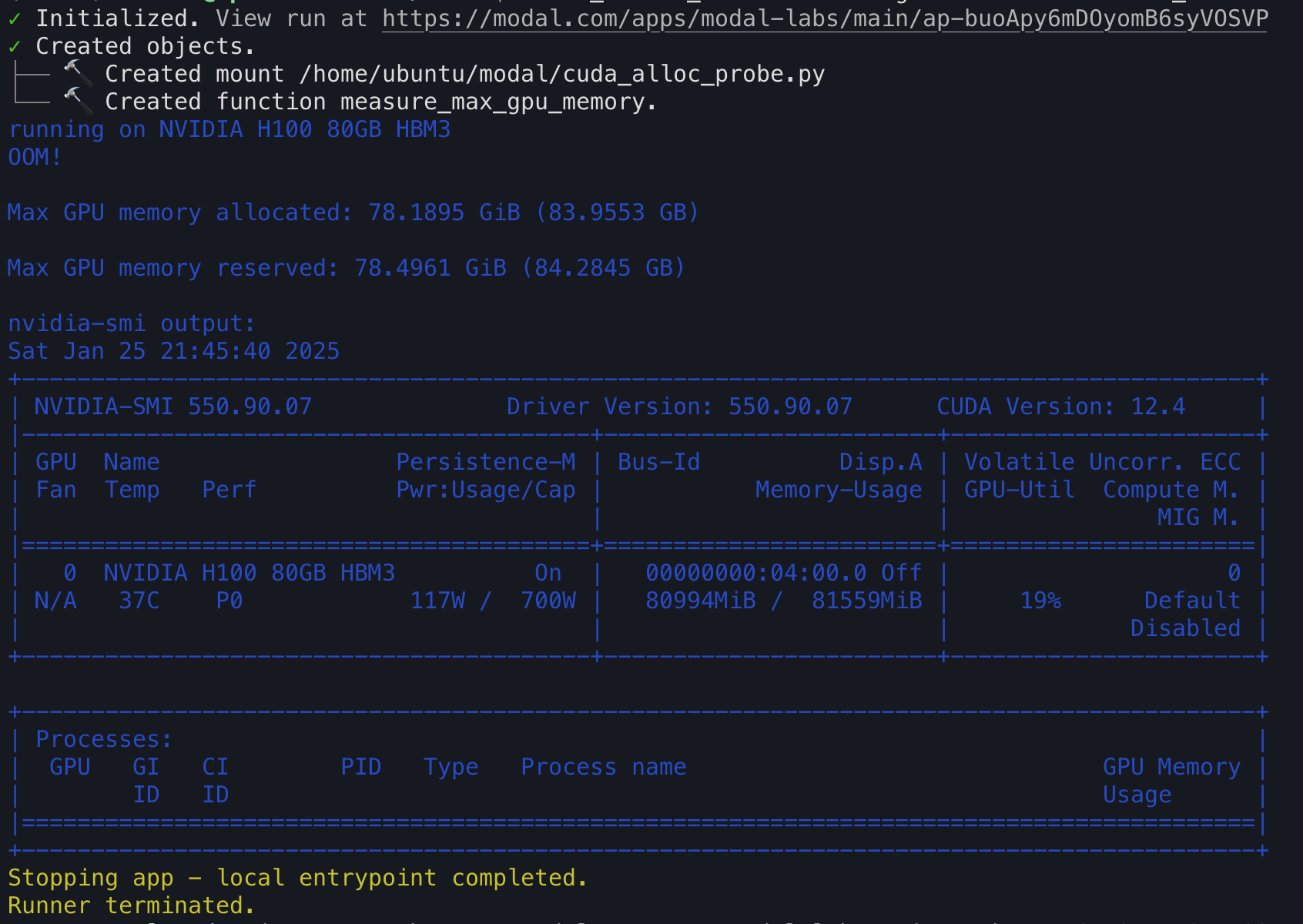
We have three memory usage numbers here:
max_memory_allocated→ 83.9553 GBmax_memory_reserved→ 84.2845 GBnvidia-smi→ 84.9283 GB (80,994 MiB)
‘Allocated’ is how much our application is storing, ‘reserved’ is how much the intermediary PyTorch CUDA caching memory allocator is storing, and the last is NVML’s view on how much is allocated.
NVML at least thinks we’ve allocated everything! After summing the PyTorch application’s storage of zeroed-out tensors and the device’s reserved memory, all 85.52 GB is exhausted.
It’s curious that PyTorch’s allocator shows less than NVML. I don’t know why that is yet.
So we’ve found that on a GCP H100 instance (a3-highgpu-8g) we can in fact allocate 6.1% more memory than the product specs promise (84.93 GB vs 80GB).
Now the question becomes: why does NVIDIA overdeliver on memory, and especially so for the later Ampere and Hopper generations?
Why give more than you advertise?

The NVIDIA H100’s HBM3 memory is amongst the most expensive components of the roughly $25,000 USD GPU. At NVIDIA’s scale a 6% overhead on cost of components is billions of dollars, so what’s going on?
We’re now pushing to ask questions of hardware parts in an H100 chip, and it’s at this point that Google (and sure, Claude) started to turn up thin gruel. I almost always operate at the ‘cloud layer’ and so my knowledge and search capabilities are poor when it comes to hardware, but I think Anandtech and SemiAnalysis offered a semi-satisying answer.
The H100’s VRAM is SK Hynix HBM3 (high-bandwidth memory generation 3). Each HBM3 stack is 16GB (the product marketing GB, not GiB) and the while the H100 has six of these, only five are active, for a total of 80GB1. Now, we know that while the industry advertises in base-ten it builds in base-two. The actual capacity of a SK Hynix HBM stack is more than 16GB, and part of that capacity will be ‘bad’, as in faulty or dead memory cells. The manufacturer has to sell and deliver their memory chips capacity at the maximum it can reliably yield.
NVIDIA takes this memory chip from SK Hynix along with its memory cell failure rate stats and sets its own max memory capacity according to the cell failure rate and the expected useful life of the chip. NVIDIA needs X MiB of memory cell overprovisioning so that it can substitute in good cells when bad ones fail. They call this “row remapping” on new architectures, and “page retirement” on older architectures. SSDs have a very similar bad cell problem and do their own “memory overprovisioning” which reserves extra memory that can be mapped into service when needed.
So I’ll speculate that the extra 5.52GB comes from SK Hynix HBM3 chips being manufactured with more than 16GB, but ‘bad’ cells are inevitable and thus SK Hynix and NVIDIA must manage this yield problem to set a consistent, minimum level of actual allocatable memory on delivery. For the H100 this minimum is a bit below 80 GiB (79.65 GiB) but well above 80 GB (85.52GB).
But this is pretty hand wavy! I’d love to drill down further, but I get the sense that the technical specs involved here aren’t intended for my eyes.
-
https://www.servethehome.com/nvidia-h100-hopper-details-at-hc34-as-it-waits-for-next-gen-cpus/ ↩